RoCE 网络协议
全面调研报告
深度解析RDMA over Converged Ethernet技术原理、性能优化策略、应用场景及市场发展趋势
执行摘要
RoCE(RDMA over Converged Ethernet)是一种革命性的网络协议,它允许在标准以太网基础设施上实现远程直接内存访问(RDMA)功能。通过绕过操作系统内核和CPU,RoCE实现了服务器间内存到内存的超低延迟、高带宽数据传输。
性能优势
端到端延迟低至1微秒,CPU卸载率达95%以上
部署灵活
兼容现有以太网基础设施,支持三层路由
市场趋势
预计2027年将成为AI网络主流技术
1. RDMA技术基础
远程直接内存访问技术的核心概念、优势及分类
RDMA核心概念
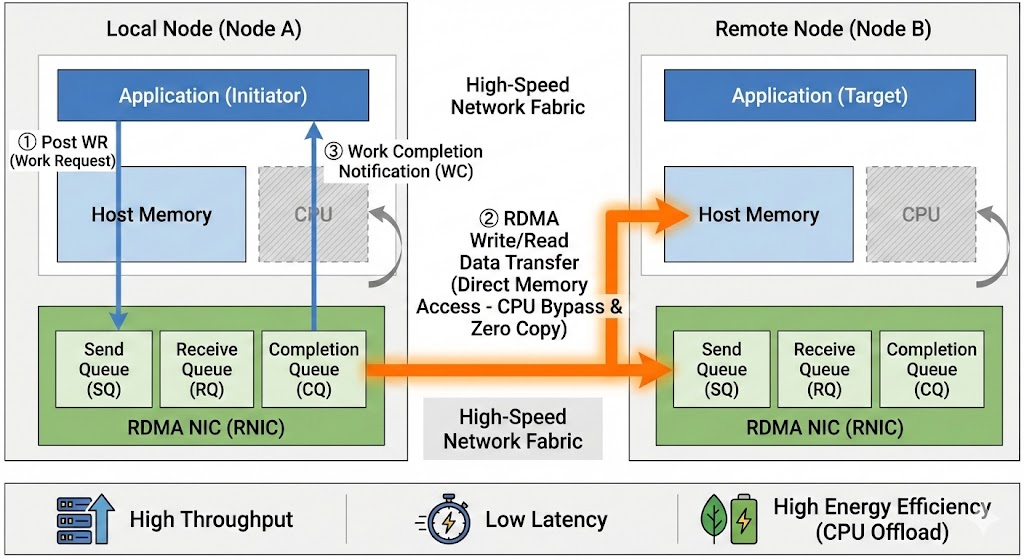
RDMA三大技术优势
2. RoCE技术原理与协议细节
深入解析RoCE协议架构、版本演进及数据包格式
RoCE v1:链路层实现
基于以太网链路层 (Layer 2)
只能在同一广播域内通信
Ethertype标识:0x8915
特定以太网类型标识RoCE流量
协议栈简单,延迟极低
无需IP和UDP层处理
RoCE v2:网络层实现
基于UDP/IP协议栈 (Layer 3)
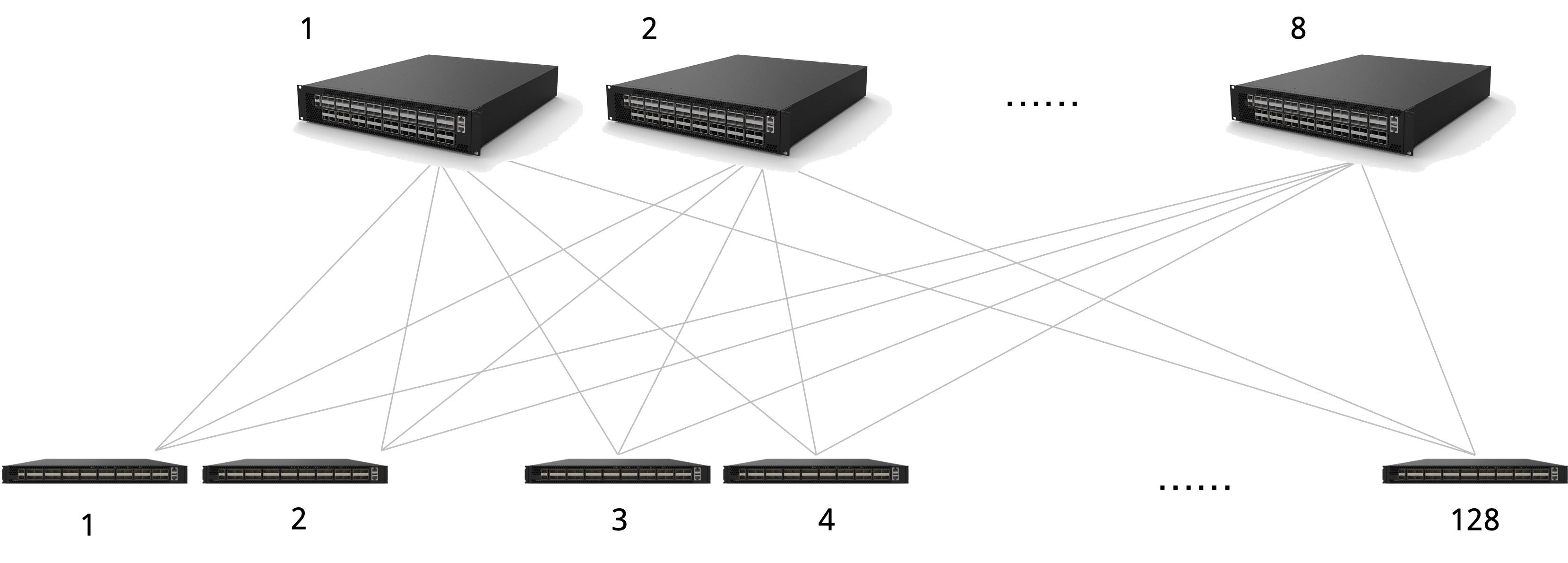
支持三层路由和跨子网通信
UDP目的端口:4791
固定端口标识RoCE v2流量
支持ECMP负载分担
基于UDP源端口号进行哈希
RoCE v2数据包结构解析
1. 以太网头部
包含源MAC地址和目的MAC地址,用于二层网络寻址
2. IP头部
包含源IP地址和目的IP地址,用于三层网络路由
3. UDP头部
目的端口固定为4791,源端口用于ECMP负载分担
4. InfiniBand基础传输头 (BTH)
包含操作码、目的队列对号(Dest QP)和包序列号(PSN)

关键标识符
3. RoCE性能优化与拥塞控制机制
构建无损以太网环境,实现高效拥塞控制
无损以太网构建
问题
RDMA对丢包极为敏感,极低丢包率导致性能急剧下降
解决方案
通过DCB技术构建无损以太网,避免数据包丢失
目标
在网络拥塞时通过流量控制避免丢包,而非简单丢弃
PFC流量控制
基于优先级的流量控制,实现精细化拥塞管理
- • 8个优先级队列
- • XON/XOFF阈值控制
- • 逐跳流量控制
ETS带宽管理
增强传输选择,保证带宽公平分配
- • 带宽保证机制
- • 优先级调度
- • 防止流量饥饿
DCBX自动协商
数据中心桥接交换,实现配置同步
- • 自动配置发现
- • 端到端同步
- • 简化部署管理
显式拥塞通知(ECN)
ECN能力协商
通信双方协商启用ECN功能
拥塞标记
交换机将ECN字段修改为"11"
CNP通知
接收端向发送端发送拥塞通知包
速率调整
发送端启动拥塞控制算法降低速率
ECN标记状态
DCQCN算法
三大状态
速率调整机制
• 收到CNP:速率降至5/6
• 无CNP:逐步增加探测带宽
• 空闲状态:快速增加利用率
4. RoCE应用场景与部署案例
从高性能计算到金融交易,RoCE在各行业的实际应用
高性能计算(HPC)
在HPC领域,RoCE技术被广泛应用于加速并行计算任务。气候模拟、分子动力学建模等应用通过RDMA实现节点间内存直接读写,将通信延迟降低至微秒级别。
数据中心与云计算
在现代数据中心,RoCE成为构建高性能低延迟网络的核心技术。AI大模型训练、分布式存储等场景下,RoCE将GPU集群间通信延迟压缩至2-5微秒。
金融行业高频交易
金融行业对网络延迟要求达到极致。RoCE凭借超低延迟特性,成为构建高频交易系统的理想选择,交易指令和市场数据以最快速度传输。
存储网络(NVMe over RoCE)
NVMe over RoCE通过标准以太网基础设施,实现对远程NVMe SSD的低延迟、高带宽访问,为数据中心提供高性价比存储网络方案。
实际部署案例分析
中国工商银行高性能存储网络转型
工商银行率先启动高性能存储网络转型,选定NVMe over RoCE技术作为新一代存储网络技术路线,构建"多地多中心"高可用架构。
技术收益
- • 摆脱专有FC网络依赖
- • 实现硬件解耦
- • 供应链多样化
性能提升
- • 存储I/O性能大幅提升
- • 满足核心业务需求
- • 骨干网压力缓解
成本效益
- • 总体拥有成本降低
- • 开源标准优势
- • 运维成本优化
数据来源:[15]
中国移动数据中心应用
中国移动积极推进RoCE技术在数据中心和云计算基础设施中的应用,与合作伙伴共同推进以太无损网络测试方案的标准化工作。
合作推进
- • 与是德科技合作测试
- • 提高测试效率和可靠性
- • 标准化测试方案
技术目标
- • 400G端到端高性能网络
- • 智算中心网络建设
- • AI算力网络引擎
信创领域的应用实践
在信创背景下,RoCE技术凭借开放性和标准以太网优势,成为实现网络基础设施国产化替代的重要技术路径。
交换机层面
- • 华为、新华三成熟方案
- • 锐捷网络产品支持
- • 国产替代方案
网卡层面
- • 华为自研网卡产品
- • 国际主流网卡接受
- • 信创场景应用
存储层面
- • 华为OceanStor支持
- • 宏杉科技高端产品
- • NVMe over RoCE方案
数据来源:[18]
5. RoCE与其他RDMA技术对比
深度分析InfiniBand、RoCE、iWARP的技术差异与选型考量
RoCE vs InfiniBand
协议栈层级
性能差异
- • InfiniBand延迟和带宽略优于RoCE
- • RoCE v2性能已接近InfiniBand水平
- • 随着以太网技术进步,差距不断缩小
成本与部署
InfiniBand
专用硬件昂贵,运维成本高,需要独立建网
RoCE
复用现有以太网,硬件成本低,部署简单
可扩展性
RoCE v2支持三层路由,适用于大规模数据中心网络部署,而InfiniBand在超大规模HPC集群中具有优势。

生态系统
RoCE vs iWARP
协议栈与实现方式
RoCE v2
基于UDP/IP协议栈
- • 绕过复杂TCP协议栈
- • 更低延迟和协议开销
- • 需要PFC/ECN保证无损
iWARP
基于TCP/IP协议栈
- • 利用TCP可靠传输机制
- • 兼容现有IP网络
- • 适合广域网环境
性能与兼容性对比
性能表现
兼容性
iWARP基于标准TCP/IP,理论可部署在任何IP网络中。RoCE需要交换机支持DCB功能,但随着现代数据中心交换机对DCB的普遍支持,这一限制正在减弱。
RDMA技术选型决策矩阵
| 考量维度 | InfiniBand | RoCE v2 | iWARP |
|---|---|---|---|
| 性能 | 最优 | 优秀 | 良好 |
| 成本 | 最高 | 中等 | 中等 |
| 部署复杂度 | 高 | 中 | 低 |
| 可扩展性 | 高 | 高 | 中 |
| 生态系统 | 封闭 | 开放 | 较小 |
| 适用场景 | 超算中心、大型AI训练 | 云数据中心、AI、存储 | 广域网RDMA、企业应用 |
技术选型建议
选择InfiniBand
追求极致性能,预算充足,大型HPC或AI集群场景
选择RoCE v2
希望在性能和成本间取得平衡,基于以太网的数据中心
选择iWARP
需要利用现有IP网络长距离通信,部署简单性要求高
6. RoCE市场趋势与主要厂商方案
全球市场增长预测、中国本土发展及生态系统建设
全球市场增长预测
中国市场发展动态
市场需求驱动因素
AI大模型发展
高性能计算集群需求激增
云基础设施投资
BAT持续加大AI基础设施投入
信创政策推动
国产化替代需求强烈
运营商集采情况
全球主要厂商
NVIDIA (Mellanox)
市场领导者
• ConnectX系列网卡
• Spectrum交换机系列
• DOCA软件框架
• 25G-400G全覆盖
Intel
生态整合专家
• E810系列网卡
• 原生RoCE v2支持
• CPU/芯片组深度集成
• DPDK/SPDK支持
Broadcom
芯片设计专家
• 400GbE单端口方案
• N1400GD适配器
• P1400GD网卡
• 第四代RoCE技术
数据来源:[23]
生态系统与标准化进展
标准组织
• IBTA定义RoCE标准
• IEEE推动PFC/ECN
• IETF相关协议标准
开源社区
• Linux原生支持
• DPDK/SPDK支持
• 丰富驱动和工具
产业链
• 芯片到软件全覆盖
• 厂商紧密合作
• 完整产业生态
超以太网联盟(UEC)作用
UEC汇聚了全球顶尖科技公司,致力于构建面向HPC和AI计算的高性能传输层协议,RoCE是其重要技术基础。NVIDIA、Broadcom、Intel等巨头共同参与,加速了RoCE生态系统的发展。
数据来源:[23]